TCP 的可靠性
Posted: 11.12.2019
介绍
我们都知道 TCP 比起 UDP,无疑是非常可靠的。
可是 TCP 的可靠性究竟体现在哪些方面呢?
其实主要有如下的方面:
- 校验和
- 序列号 + 确认应答
- 超时重传
- 连接管理
- 流量控制
- 拥塞控制
校验和
也就是 Checksum。这玩意儿不仅是 TCP 有,就连 UDP 也有,可以算是 UDP 唯一的可靠性保证了。
这个时候就又要请出这张图了:

我们可以看见,校验和就在左下角,一共 16 bit。
那么校验和是怎么进行计算的呢?
伪首部
首先,我们必须要引入伪首部这个概念。
我们知道,IP 与 TCP 这两个协议之间,整个 TCP 的报头+数据 = IP 的数据。如下图:
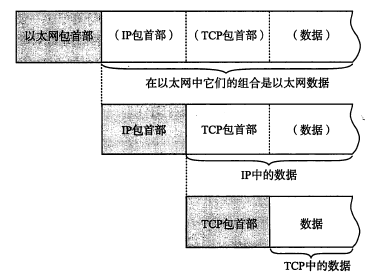
如果把两个协议完整展示出来的话,如下:
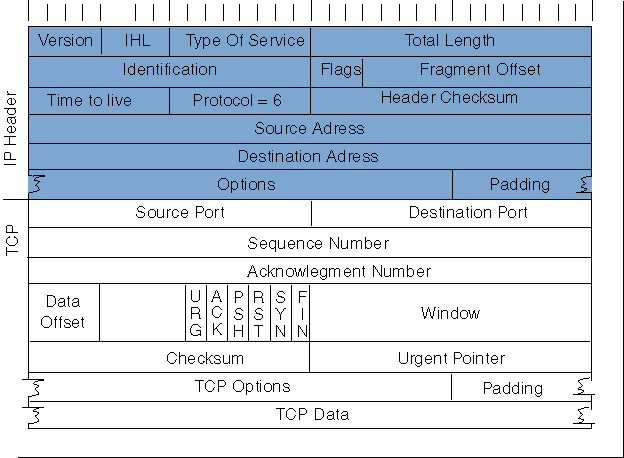
这里就不细讲了,感兴趣的小伙伴自己去了解吧。
那么问题来了,伪首部就是 IP 的首部吗?
并不。TCP 的伪首部只会取 IP 首部其中的 Source Address 和 Destination Address。
并且还会额外加上 0s,协议,以及 TCP 协议的长度。如下图:

添加了伪首部后,我们才能够开始计算校验和。
计算校验和的方式就是,我们把从伪首部开始,所有的内容都切分成 16 bit 长度的片段(因为校验和的长度为 16 bit),然后把这些片段都加起来,如果有进位的话,最后再 +1,然后再取反。
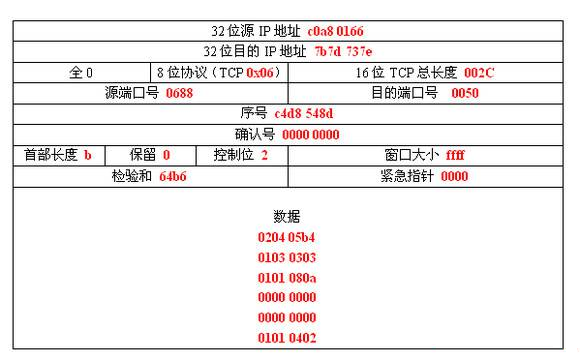
在上面的图里,我们每次都取 16 个 bit 的数据(也就是 4 个 hex 字符),然后相加:
0xc0a8 + 0x1066 + 0x7d7d + ... + 0x0101 + 0x0402 = 0b1 0000 0000 0000 0000(假如这是最后的结果)
注意,这个数字最后有一个进位,于是我们把这个进位加到最后,得到:0b0000 0000 0000 0001
然后我们再取反,得到 0b1111 1111 1111 1110,这就是我们最终得到的校验和。
那么接收方要如何验证这个校验和呢?其实很简单:接收方收到数据后,对数据以同样的方式进行计算,求出校验和,与发送方的进行比对。
如果数据被改变了,那么接收方计算出来的校验和,和 TCP 里包裹的校验和是不一样的。
不过这样又导致了一个问题,那就是,如果攻击者篡改了 TCP 的数据,然后根据那个数据来计算校验和(因为计算校验和的方法是固定的),然后把那个校验和放到 TCP 的首部里,接收方计算出来的校验和就是攻击者算出来的校验和,是无法验证数据是否被更改过的。
因此,校验和只是可靠性的一个保证,但并不是唯一的保证。
序列号 + 确认应答
其实就是 syn 与 ack 这两个分别为 16 bit 的数据。
并不是只有三次握手的时候才会用到 syn 和 ack,而是每次接收方收到数据后,都需要发送 ACK = 1 的报文进行确认。
假设 Window Size 为 100,也就是说,发送方每次发送 100 个 segment 给接收方。
发送方的报文:seq = 0
接收方的报文:ack = 101(因为接收到了 100 个 segment,所以希望下一次从 101 开始)
发送方的报文:seq = 101
接收方的报文:ack = 151(发生了丢包,只收到了 50 个 segment,所以希望下一次从 151 开始)
发送方的报文:seq = 151
...
超时重传
这部分我不太熟悉,所以整个超时重传的部分都是摘抄的,网络基础:TCP协议-如何保证传输可靠性
在进行TCP传输时,由于确认应答与序列号机制,也就是说发送方发送一部分数据后,都会等待接收方发送的ACK报文,并解析ACK报文,判断数据是否传输成功。
如果发送方发送完数据后,迟迟没有等到接收方的ACK报文,这该怎么办呢?而没有收到ACK报文的原因可能是什么呢?
首先,发送方没有介绍到响应的ACK报文原因可能有两点:
- 数据在传输过程中由于网络原因等直接全体丢包,接收方根本没有接收到。
- 接收方接收到了响应的数据,但是发送的ACK报文响应却由于网络原因丢包了。
TCP在解决这个问题的时候引入了一个新的机制,叫做超时重传机制。
简单理解就是发送方在发送完数据后等待一个时间,时间到达没有接收到ACK报文,那么对刚才发送的数据进行重新发送。
如果是刚才第一个原因,接收方收到二次重发的数据后,便进行ACK应答。如果是第二个原因,接收方发现接收的数据已存在(判断存在的根据就是序列号,所以上面说序列号还有去除重复数据的作用),那么直接丢弃,仍旧发送ACK应答。
那么发送方发送完毕后等待的时间是多少呢?如果这个等待的时间过长,那么会影响TCP传输的整体效率,如果等待时间过短,又会导致频繁的发送重复的包。如何权衡?
由于TCP传输时保证能够在任何环境下都有一个高性能的通信,因此这个最大超时时间(也就是等待的时间)是动态计算的。
连接管理
连接管理就是三次握手和四次挥手的机制。
具体的可以参考这篇文章:TCP 三次握手 / 四次挥手
流量控制
这个时候就又要请出这张图了:
我们可以看见,TCP 首部右下角有一个窗口大小(Window Size),一共 16 bit。
这个窗口大小就指定了 TCP 携带数据的大小。
我们知道,如果两台机子建立了 TCP 连接,其中一台很强,能发送大量的 traffic,但是另一台是很旧的机子,能力不行,处理不了太多的 traffic。这个时候如果第一台机子一直往第二台机子发送流量,那么第二台机子只能不接受,这就导致了丢包。
因此,我们需要利用流量控制,来控制第一台机子发送流量的大小。
而发送流量的多少,自然是由接收方来通知发送方的。接收放会在确认应答发送确认报文时,将自己的即时窗口大小填入,并跟随确认报文一起发送过去。而这个窗口大小,就是目前接收方空余的缓冲区(buffer)的大小。空多少就接受多少,不贪。
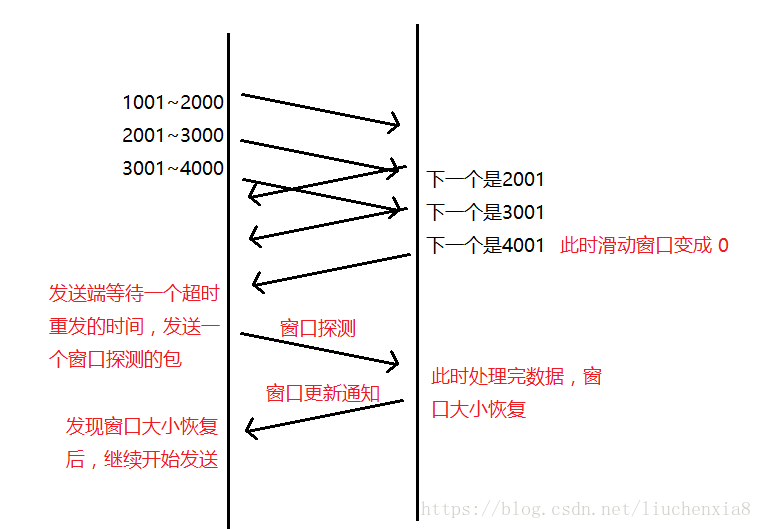
如果窗口大小被设置成 0,那么发送方就会停止发送数据,并且等待一个超时重传的时间,并发送一个窗口探测的包。
接收方如果处理完了数据,缓冲区空了出来,于是更新了窗口大小。发送方知道了新的窗口大小,根据此继续发送。
其过程如下图所示:
拥塞控制
我们用迅雷下片的时候,会发现一开始速度会很慢,可能只有 100kb 左右,然后才在一个比较短的时间内,逐渐提升到 10mb 左右。
这其实就是 TCP 的拥塞控制机制。因为一开始我们不知道网络的状况,如果一开始就暴躁传输,很有可能会丢包。因此,TCP 会采用慢开始的算法。先从小的流量开始试探,最后再稳定在一个较为平稳的地方。
并且,TCP 的拥塞控制一共分为三个部分:
- 慢开始
- 拥塞避免
- 快重传 + 快恢复
整体来看就是下面这张图:
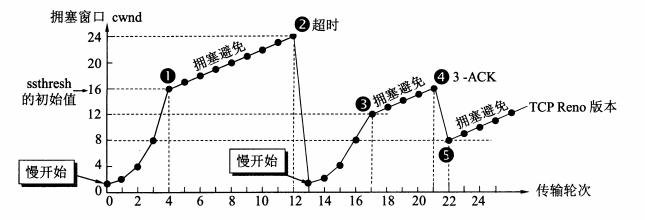
究竟在什么时间该用什么部分,这是由慢开始门限来决定的
慢开始门限
慢开始门限便是 ssthresh,指定了究竟在什么时候用慢开始算法。
而与慢开始门限所对应的,便是拥塞窗口(cwnd),代表了窗口的大小与拥塞程度。
而决定使用哪种算法的,一共有四条规则:
- 当 cwnd < ssthresh 时,使用慢开始算法
- 当 cwnd > ssthresh 时,停止使用慢开始算法,改用拥塞避免算法
- 当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞控制避免算法
- 无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认 ack),就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为1,执行慢开始算法
慢开始
一开始先把 cwnd 设置成 1(一个最大报文段 MSS 的数值,也就是一个 segment)。
然后以指数级的方式翻倍,1 --> 2 --> 4 --> 8 --> 16 --> ...
慢开始的 慢 并不是指 cwnd 的增长速率慢,毕竟指数级的增长方式快到爆炸了好吧。
它的慢指的是从一个很小的数字开始增长。
拥塞避免
刚才用了慢开始以后,窗口大小呈指数级增长,这样下去接收方很快就撑不住了。
因此,在超过慢开始门限后,要使用拥塞避免的算法。
拥塞避免的算法是线性增长的:1 --> 2 --> 3 --> 4 --> ...
这比慢开始算法的拥塞窗口增长速率缓慢得多,这样网络比较不容易出现拥塞。(但这并不意味着完全避免拥塞,这和拥塞避免这四个字的概念不太一样,只是减小了出现拥塞的概率而已)
TCP Tahoe 版本
在 TCP Tahoe 的版本(现在已经不用了),超时出现后(也就是窗口过大,开始出现丢包以后),我们会直接用慢开始算法,从 1 开始。也就是图片里指出来的部分。
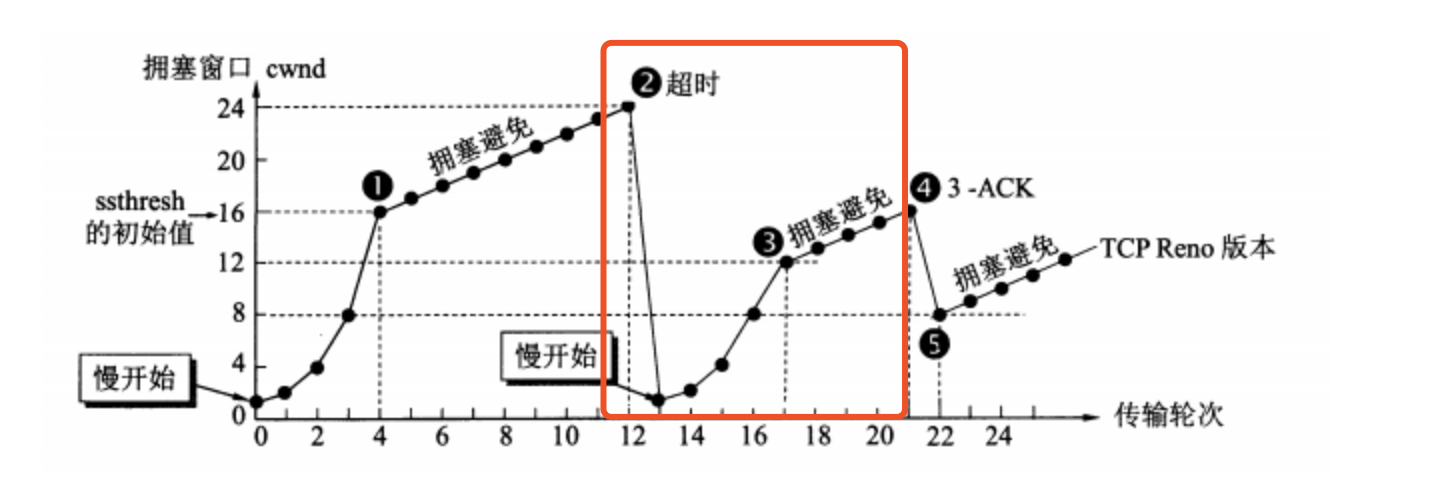
我们可以看见,在这个版本,是没有快重传与快恢复的。
快重传
在 TCP Reno 版本开始使用,并且配合快恢复一起使用
快重传要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时捎带确认。
快重传算法规定,发送方只要一连收到三个重复确认(ACK)就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器 RTO 时间到期。
由于不需要等待设置的重传计时器到期,能尽早重传未被确认的报文段,能提高整个网络的吞吐量。
快恢复
在 TCP Reno 版本后开始使用,并且配合快重传一起使用
当发送方连续收到三个重复确认时,就执行乘法减小算法,把 ssthresh 减半。
考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。
所以此时不执行慢开始算法,而是将 cwnd 设置为 ssthresh 的大小,然后执行拥塞避免算法。如下图:
